GISと空間解析
概説
土木計画の策定過程では、前節までに示した空間情報技術を通して取得した地形や土地被覆、土地利用などを表す自然・都市環境データに加え、人口構成や世帯所得分布、産業の経済活動などを表す社会経済データを勘案して、地域の現状を分析・把握し、その将来像を議論することが求められます。
地域分析に必要な情報の大半は、空間的位置との関連性を有する空間情報です。空間情報は、実空間上に存在する実体を空間データモデルに基づき抽象化したものです。この空間情報を、空間的な位置を鍵に統合的に管理し、空間的近接性を考慮した分析やその結果の共有・可視化などを通して、地域の自然環境や社会経済状況の分析できる環境を提供する情報システムが、地理情報システム(geographic information system, GIS)です。
GISの特徴は、空間的位置に基づく情報管理にあります。位置表現には、平面位置のみでも二次元が必要で、一次元の識別子による管理に比べ複雑です。さらに、線や面による抽象化が必要な実体は、多数の頂点座標による表現が必要です。そのため、空間的位置に基づく管理はデータ量が多く、その解析は計算負荷が大きいため、効率的な情報の管理や処理が不可欠となります。そこで、本節では、GISによる空間情報の効率的な管理・分析を支える要素技術を解説します。
空間データモデル
空間データモデルは、実体の空間的な位置や形状を表す幾何学的属性の表現方法により、二つに大別できます。
一方は、実体を空間上の離散的事象と捉えて地物として抽象化するモデルで、その位置や形状を点・線・面などの空間オブジェクトを用いてベクター形式で表現します。
他方は、実体を空間上の連続的事象と捉え、すべての地点に属性値を対応させたフィールドとして抽象化するモデルで、格子領域などの小領域への空間分割を通してフィールドを近似したラスター形式で表現します。
さらに、地物に基づいて抽象化するベクター形式の空間データモデルは、各空間オブジェクトを地物として管理するレイヤーモデルと、複数の空間オブジェクトから地物を定義して管理するオブジェクトモデルに分類できます。
幾何学的属性の表現
前述のように、実体を離散的事象と考える地物に基づく抽象化ではベクター形式、実態を連続的事象と考えるフィールドに基づく抽象化ではラスター形式で幾何学的属性を表現します。また、地形を表す標高値は連続的事象とみなせますが、ベクター形式の一種である不規則三角形網(triangulated irregular network, TIN)による表現も使用されます。
これら空間情報のデータ表現に用いられる3種類の幾何学的属性の表現方法について説明します。
ベクター形式
ベクター形式とは、実体の属性のうち、空間的な位置や形状など幾何学的属性を点・線・面などの空間オブジェクト(spatial object)で抽象化し、その頂点座標を記録して表すデータ形式です。地物は、幾何学的属性とその他の属性を連結したデータとして表現されます。
なお、点・線・面のいずれの空間オブジェクトによる表現が適切かは、情報の使用目的や分析・表現の空間縮尺に依存します。例えば、都市の位置を表す空間情報は、全世界を対象とした分析では点、都市圏を対象とする分析では面で表現するのが適切でしょう。
また、空間オブジェクト間の隣接関係や接続関係など、空間的な関連性を表す位相(topology)を、明示的に表現できるベクター形式のデータモデルが考案されています。位相を表現できるデータモデルを用いると、例えば交差点を点、交差点間の道路区間を線で表し、線が点を介して接続する位相構造を記録して道路網を表現することや、土地の筆界を面で表し、境界線や境界線上の点が複数の面に共有されている関係を記録して筆界の隣接関係を表現することができます。
ラスター形式
ラスター形式は、矩形領域を同じ形状の矩形格子に分割し、矩形領域の端点座標、縦横方向の格子数・間隔、各格子の属性値を記録するデータです。標高や土地利用など、領域内の任意地点に関するデータを取得可能な事象の表現に適しています。また、格子状の地域分割に基づき集計された、国勢調査や経済センサスなどの地域メッシュ統計も、ラスター形式で表現できます。
ラスター形式は格子点座標を記録する必要がないため、特に広領域を覆う高解像度のデータではデータ量を圧縮できます。また、同一の格子設定に基づく複数データを用いた分析は容易に実行できます。しかし、格子位置や間隔が異なるデータの分析には支障が多いです。また、空間解像度を部分的に変えられないことも限界です。
例えば、細かい起伏が連続する山地と滑らかな地形の平地を含む地域の標高を記録する場合、ラスター形式では、地域的に過剰あるいは過小な空間解像度でデータを作成せざるを得ません。
不規則三角形網
不規則三角形網では、ベクター形式を用いて空間上で連続的な事象を表します。属性値が与えられた点と、それらの点を母点として構成した三角網の面から成ります。点以外の場所の属性値は、その場所を内包する三角形の3頂点の属性値、座標を用いて線形補間した値とします。
不規則に分布する母点を基準に作成する三角網は、通常、三角網の最小の内角を最大化するドローネ三角網を用いて構築します。ただし、地形を表現する場合、ある2点を結ぶ線が尾根線や谷線に当たることが既知なら、その線が三角網の辺となるように三角網を構成すると、実地形に近い抽象化が可能になります。
TINでは点の配置を調整できるため、ラスター形式とは異なり、空間解像度を部分的に調整することが可能です。ただし、同水準の空間解像度でデータを作成するとTINはラスター形式に比べてデータ量が大きいため、情報管理や分析の計算負荷が増大します。
ベクター形式の空間データモデル
地物に基づく実体の抽象化を行うベクター形式では、レイヤーモデルとオブジェクトモデルの2種類の空間データモデルが用いられます。
レイヤーモデル
レイヤーモデルとは、地物の幾何学的属性を空間オブジェクトで表し、幾何学的属性以外の属性をそれぞれの空間オブジェクトに関連付けて表現するデータモデルです。
ここで、道路網をレイヤーモデルで表すため、「道路区間」と「交差点」を地物と考え抽象化する場合を考えましょう。「道路区間」の位置や形状などの幾何学的属性を線の空間オブジェクトで、地物「交差点」の位置を点の空間オブジェクトで表した上で、道路区間の車線数や交差点の名称など、幾何学的属性以外の属性は、それぞれの地物の各空間オブジェクトと関連付けて記録します。
この二つのデータを空間的位置に基づいて層状に重ね合わせると、道路網構造の情報が得られますが、レイヤーモデルでは「道路区間」と「交差点」の関係を明示的に記述できません。もちろん、「道路区間」属性として端点の交差点IDを記録し、「交差点」属性として接続する「道路区間」のIDを記録すると、道路網の位相構造を表現はできますが、それらの属性を活用した問合せ手順は、レイヤーモデルでは記述できません。
また、複数の道路区間がつながって一つの道路路線を形成することを表現するためには、道路区間の属性として共通の路線IDを付加しなければなりません。
オブジェクトモデル
オブジェクトモデルとは、オブジェクト指向の枠組みに基づき、複数の空間オブジェクトやそれらの組合せで構成される地物を、空間オブジェクト・地物間の関係やその関係を利用した情報処理手順と合わせて記述できる空間データモデルです。クラスと呼ばれるオブジェクト内に空間オブジェクトや地物を定義し、クラス間には階層構造などの関係を定義します。
オブジェクトモデルで道路網を表現する例について、クラスの関係を図-1に示します。ここでは、「道路網」の下位クラスとして「路線」や「交差点」を、さらに「路線」の下位クラスとして「道路区間」を定義し、道路区間の幾何学的属性として、線の空間オブジェクトを用いて表す「区間」を定義します。
「路線」属性として「名称」を定義すると、「路線」の下位クラスの「道路区間」に継承されるため、「道路区間」の検索に路線名称を用いることができ、レイヤーモデルとは異なり「路線」と「道路区間」の関係を明示的に記述できます。
また、オブジェクトモデルでは、「道路区間」の端点が「交差点」という関係を明示的に記述でき、その関係を利用��して「交差点」を介して接続する「道路区間」の検索手順も記述できます。
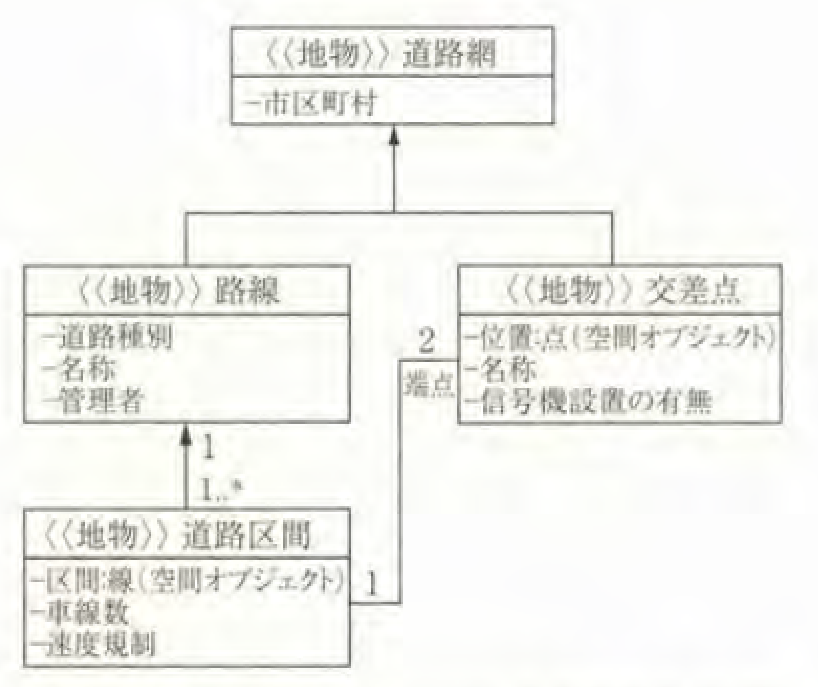
図-1:道路網のオブジェクトモデルのクラス図
データベースと空間解析
GISでは一般に、データベース管理システム(database management system, DBMS)を用いて空間データを管理します。DBMSを用いるおもな利点を以下に示します。
-
ハードディスクなど二次記憶装置を用いたデータ管理をDBMSに任せて効率化し、データの物理的格納状態を知らずに利用できます。
-
大規模データに対しても、高速にデータの追加・削除・更新や検索・利用ができます。
-
データに索引を容易に構築することができ、データ検索を高速化できます。
-
データベースへの問合せ言語であるクエリーを用いて複雑な検索・分析条件を簡潔に記述でき、索引を利用して効率的に処理できます。
空間データを扱えるよう拡張された空間データベース管理システム(spatial database management system, spatial DBMS)は、空間データの管理や利用の効率化に大きく寄与しています。
本項は、まず空間データモデルで紹介したデータ構造に対応した関係データベースとオブジェクトデータベースを説明した後、空間DBMSを用いた空間データ処理のうち、空間�的位置に基づく検索である空間検索を効率化する空間索引と、空間DBMSへの問合せ言語である空間クエリーを紹介します。
関係データベースとオブジェクトデータベース
関係データベース(relational database)は、二次元の表形式の構造でデータを記録するデータベースです。一部のデータ項目を鍵に、複数の表を結合する操作が用意されており、この表結合操作を通じて、データ利用者は、複雑なデータを用いた検索処理を実行できます。関係データベースは、空間データの管理に限らず、現在、最も一般的に利用されているデータベースです。
レイヤーモデルによって作成された空間データは、関係データベースで管理されます。ただし、前述のように、複数の空間データ間の相互関係を明示的に記述することはできません。複数の空間データの関係が複雑になれば、表形式のデータとして記録することが煩雑な作業となる上、その関係を利用した検索などの操作も複雑な処理が要求されます。
一方、オブジェクトデータベース(object database)は、階層構造などクラス間の関係を定義できるデータベースです。クラス間の関係を踏まえたデータ問合せ手順を定義することも可能で、複雑な構造を持つ空間データに関する分析が容易となります。オブジェクト指向のソフトウェアとの親和性も高いです。
空間索引
索引とは、データベースに格納されているデータの検索処理を効率化するための情報および仕組みです。空間索引(spatial index)は、ある場所に最も近い地物やある領域内に存在する地物を見つける空間検索処理の効率化を図ります。
空間検索は、GIS上で最も高頻度に実行される情報処理の一つです。画面出力のような単純処理においても、出力範囲の座標指定に基づき地物が検索され、地物間の交差判定などのより複雑な空間解析においても、答えの候補となる地物を絞り込む前処理に利用されます。そのため、空間検索の効率化は、GISの情報処理を高速化する上でたいへん重要です。
空間索引のおもな手法として、格子、四分木、kd木、R木などが挙げられます。なお、R木以外は、点で表されたデータに限定的に用いられます。
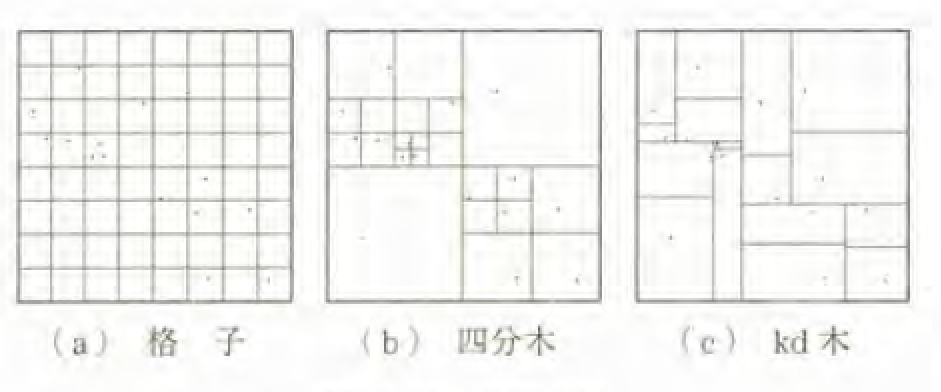
図-2:空間索引
まず、格子による空間索引は、ある領域を同じ大きさ・形状の部分領域に分割し、各部分領域に関して地物の一覧情報を整備します。なお、空間索引には、矩形格子だけではなく、三角・六角格子なども用いられます。適切な大きさの格子が構築されていると、任意地点の近隣や任意領域の内側にある地物の検索を効率化できます。ただし、部分領域の大きさはすべて等しく設定するため、地物の空間分布が偏在する場合は、検索��効率化につながりません。
地物の空間分布の不均一性を考慮し、地物が多く存在する領域を細分化した索引を作成する方法として、四分木やkd木が提案されています。
四分木を用いた空間索引は、ある矩形領域を同じ大きさ・形状の4領域に分割する操作を再帰的に繰り返し、地物が含まれる部分領域を示す索引を木構造のデータとして作成します。空間分布が疎なら木は浅く検索が早くなり、密なら木は深く検索が遅くなります。
kd木を用いた空間索引は、分割後の領域内の地物数が等しくなるよう分割する操作を縦横交互に再帰的に繰り返し、地物が含まれる部分領域を示す索引を木構造のデータとして作成します。深さ一定の平衡木を作成できるため、空間分布の粗密に伴う検索速度の不均衡を解決できます。しかし、地物の追加や削除に応じて木構造を変更できないため、データ更新に対して平衡木を保てません。
一方、R木は、データ更新にも対応して平衡木を作成でき、線や面など大きさを持つ地物にも適用できる空間索引で、多くの空間DBMSで採用されています。地物の存在領域を最小外接矩形で指定し、索引を作成します。検索では、条件に合う最小外接矩形を抽出した後、地物の詳細形状を利用して検索条件を満たすかの最終判定を行います。
図-3:最小外接矩形
図-4にR木の例を示します。最下層の葉ノードに記録されたr1-r10は、地物の最小外接矩形を表します。内部ノードは、下位階層の子ノードへの参照と、その子ノードの最小外接矩形をすべて包含する最小外接矩形(R1-R6)を持ちます。R木の各ノードから出る枝の数は可変で、図の例では最大3です。
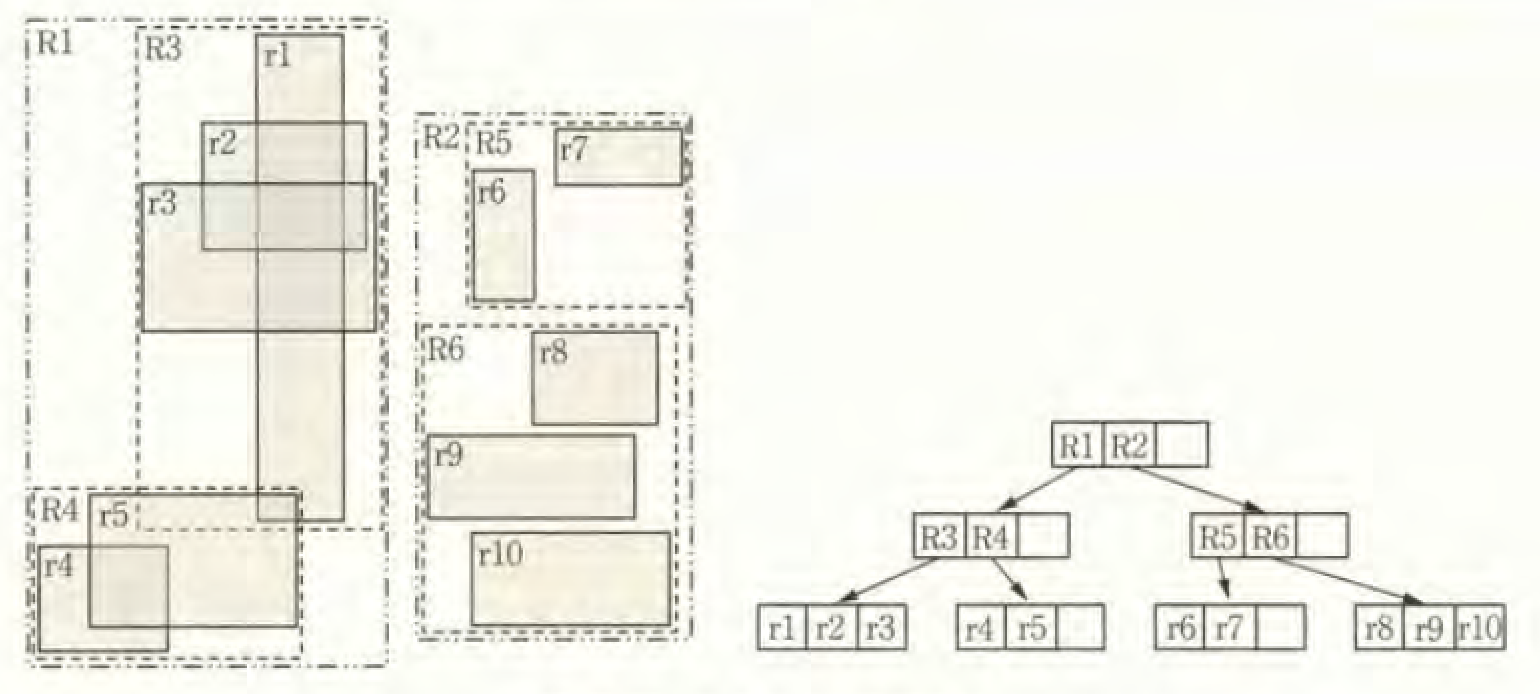
図-4:R木による空間索引
新たな最小外接矩形をR木に挿入する場合、内部ノードの外接矩形を使い、近い最小外接矩形が同じ葉ノードに属するように調整します。枝に空きがない場合には、内部ノードの分割を行ってR木を再構成します。
R木を用いると、上位階層の最小外接矩形から探索条件を確認すると探索範囲を限定できるため、空間検索を効率的に実行できます。
空間クエリー
空間クエリー(spatial query)とは、空間解析処理を空間DBMSに要求する問合せ言語です。主要な空間解析処理を関数化し、複数の空間解析処理を組み合わせなければならない複雑な分析を、簡潔なクエリーの記述で実行できる環境を提供します。空間クエリーの代表として、空間演算子、空間データ関数、空間結合を紹介します。
空間演算子
数値に対する等号・不等号や、文字列に対する一致・不一致を返す判定などの二項演算子を、空間データ処理に拡張したものが空間演算子です。交差intersectsや内包includesなど、空間的位置関係に基づく真偽判定を行う二項演算子も空間演算子です。
空間データ関数
空間データ関数は、地物の幾何的性質を返す関数です。空間演算子としても記述できる関数(例えば、交差intersects(地物1, 地物2))に加え、以下のような関数が用意されています。
-
単項関数:
- 線の長さlength(線)
- 面の面積area(面)
- 面の重心centroid(面)
-
多項関数:
- 地物間の距離distance(地物1, 地物2)
- 地物から一定距離内の範囲buffer(地物、距離)
- 二つの地物(面)の共通部分intersect(面1, 面2)
空間結合
空間結合は、複数の異なる空間データを、交差・内包・近接などで表される空間的近接関係を基に結合する操作です。
例えば、「位置を点で表した[店]データと、位置を面で表した[町丁目]データの人口属性を用い、各店から1km以内の範囲と重なる町丁目の人口を集計する」処理は、空間結合です。この処理は、空間演算子や空間データ関数を用いると簡潔に記述できます。多くのDBMSで採用されているデータベース問合せ言語SQLの書式に従うと、店舗と人口集計結果の対応表を出力する空間クエリーは下記で記述できます。
select [店].ID, sum([町丁目].人口)
from [店], [町丁目]
where intersects(buffer([店].位置, 1km), [町丁目].位置)
group by [店].ID
さて、この処理を効率化する工夫として、「店舗から遠い町丁目については交差判定しない」ことが考えられます。店を中心とした半径1kmの円の最小外接矩形を設定し、町丁目の空間索引を活用して最小外接矩形が交差する町丁目のみを抽出すると、解析対象を大きく限定できます。
空間DBMSは、空�間索引の利用可能性を踏まえ、空間クエリーの処理を自動的に最適化する機能を有しており、空間解析の操作性の向上や高速化に大きく寄与しています。
計算幾何と空間解析
本項は、空間解析処理時間に影響を与える、空間演算子や空間データ関数として定義された情報処理の効率化について説明します。
幾何学的形状を表すデータの情報処理手法は、長年、計算幾何分野で議論され、効率的なアルゴリズムが多数提案されてきました。これらのアルゴリズムはGISに実装され、大規模な空間データを用いた空間解析の実行可能性が向上しています。
以下では、アルゴリズムの効率性評価基準である計算量・計算複雑度を説明した後、計算幾何アルゴリズムを用いてGISの空間解析が効率化されていることを確認します。
アルゴリズムの性能評価
アルゴリズムの性能は、入力データの大きさと計算時間や記憶領域量など計算資源量との関係を表す、計算量で評価します。ここでは、数列を昇順に並べる整列(ソート)問題に対するアルゴリズムを計算時間で評価する場合を例に、計算量を説明します。
バブルソートは、数列中の隣接する数値を比較し��て、順序が逆なら入れ替える操作を不要になるまで繰り返す、単純なアルゴリズムです。個の数値から成る数列を入力する場合、数列がもともと昇順なら回の比較で確認が完了します。しかし、入力数列が降順なら、結果出力までに回の比較・入替えが必要になります。このようにバブルソートは、入力数列の性質に依存して計算時間が大きく異なります。通常、アルゴリズムの計算量は最悪計算時間で評価し、入力の大きさの最大次数で表します。バブルソートの場合、計算量はオーダーであるといい、と標記します。
なお、整列問題にはより効率的なアルゴリズムが数多く提案されています。例えば、マージソートは、2本の昇順に並んだ数列を結合(マージ)する際に、各列の最小値を比較して小さい値を新たな数列に追加する、マージ操作を利用する整列アルゴリズムです。1回のマージ操作は、数値の総数に比例した計算時間で実行可能です。入力数列を二つの値から成る多数の数列に分割して整列した後、2本ずつ数列を組にしてマージ操作を階層的に行うマージソートのアルゴリズムは、個の数値に対しての階層のマージ操作で整列できるため、計算量はとなります。
なお、同じオーダーの計算量を持つアルゴリズムにも優劣があり、実装や並列処理環境の有無などによっても計算時間は大きく異なるため、計算量はアルゴリズムの絶対的評価を行うものではありません。しかし、計算量のオーダーが大きいアルゴリズムは、大規模な入��力データへの適用可能性が乏しいことを確認できるように、実用可能性を推し量る重要な情報です。
空間解析の効率化
GISにおける空間解析において用いられる、幾何的位置や形状を用いた問題を解くアルゴリズムを紹介し、効率的な解法の意味について考えます。
点位置決定問題
行政区域のように、ある一定領域が複数の領域に分割された面に対して、質問点がどの面の内側に位置するかを判定する問題である。GISで面データを表示しマウスのクリックで面を指定して属性情報を閲覧する操作に相当する。
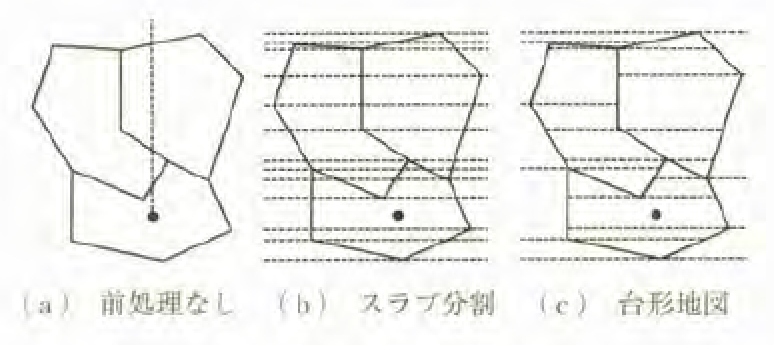
図-5:点位置決定問題
まず、問題を効率的に解くための前処理を行わない場合、点位置決定問題を解くには、質問点から鉛直方向に延ばした半直線と面の辺の交差回数を数え、奇数回交差する面を見つけなければならない(図-5(a)参照)。面の頂点数(辺数)が入力の大きさで、この計算量はとなる。
この検索を効率化するため、面の各頂点から水平線を引き、領域をスラブに分割する。つぎに、スラブ内を交差する辺の水平方向座標を記録したデータを作成する(図-5(b)参照)。このデータの作成には、の計算時間を要する。しかし、このデータを用意しておくと、質問点が与えられたときに鉛直座標を用いて質問点があるスラブを二分探索で検索し、つぎに�、スラブ内を交差する辺の水平座標を用いた二分探索および辺の上下判定を行えば、質問点が位置する面を検索できる。この処理はの計算時間で実行できるが、前処理で作成されるデータが多いという問題を抱える。そこで、面ごとに、頂点を通る水平線と辺で囲まれた領域に分割した台形地図(図-5(c)参照)と呼ばれるより効率的なデータを作成して対応する。
ボロノイ図作成問題
空間領域に配置された複数の母点に対して、領域内の任意の点がどの母点に最も近いかを表すように領域を分割した結果をボロノイ図という(図-6(a)参照)。この作成問題は、駅の位置が与えられたときに、駅勢圏を表す領域に地域を分割する問題に相当する。
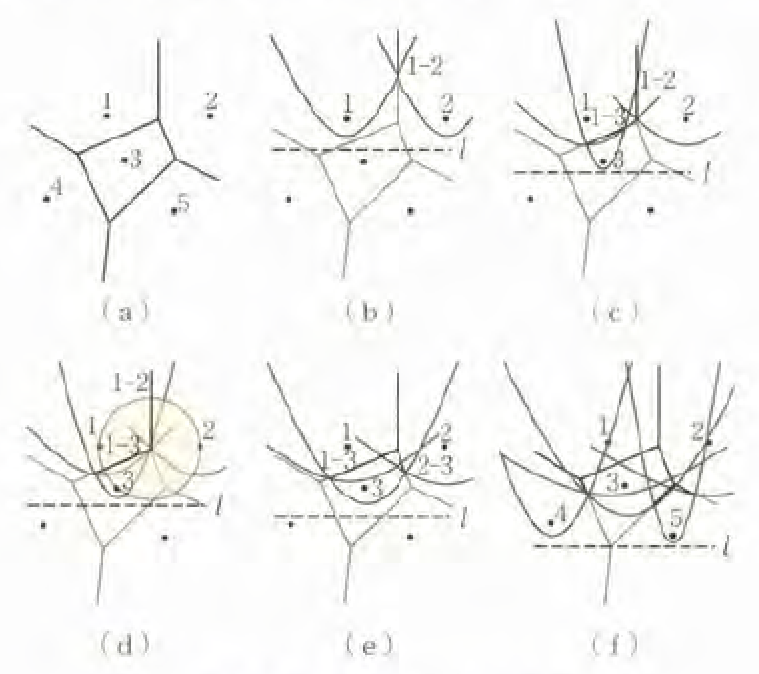
図-6:ボロノイ図作成問題
ボロノイ図の作成では、評価基準となる距離を定める必要があるが、ここではユークリッド距離を基準に分析する場合を考える。各母点に対応した領域をボロノイ面、その境界線をボロノイ辺、ボロノイ辺の交点をボロノイ頂点と呼ぶ。なお、ボロノイ辺は、それを境に隣接するボロノイ面の母点を結んだ辺の垂直二等分線、ボロノイ頂点は3点以上の母点からの等距離にある点である。なお、隣接するボロノイ面の母点を辺で結んでできる三角網は、TINでよく使用されるドローネ三角網であり、両者は双対性がある。
ここで、ボロノイ図の効率的な作成法として知られる、Fortuneのアルゴリズムの概要を示す。このアルゴリズムは、ボロノイ辺上の点が以下の手順で発見できることを利用する。
水平線を設定し、その上側にある母点に関して、母点を焦点、水平線を弧線とする放物線を描く。このとき、水平線に最も近い放物線の交点はボロノイ辺上の点となる。図-6(b)では母点1, 2を焦点とする放物線が1点で交わるが、この交点は弧線に下ろした垂線の長さが二つの母点からの距離と等しい点なので、ボロノイ辺上の点であることがわかる。水平線以下の母点までの距離は必ず垂線より長いため、水平線上の点だけを確認すればよいことも明らかである。
この性質を用いると、水平線を上から下に走査(図-6(b)〜(f)参照)し順番に母点を加えて放物線の交点を探せば、ボロノイ図を構成できることがわかる。また、3本以上のボロノイ辺が交差しボロノイ頂点を作るのは、3点以上の母点が同一円周上にあり、他の母点が円内に含まれない(図-6(d)参照)場合に限られる�ため、走査過程で、ボロノイ辺を構成する母点の組合せについてのみ、上記の条件を満たすか確認すれば、ボロノイ頂点の有無を確認できる。
以上より、母点を鉛直座標の降順に並べた後、順番に母点を追加し放物線の交点を調べてボロノイ辺を構成する母点の組合せを確認し、ボロノイ頂点の有無を調べる操作を行えば、ボロノイ図を構成できることがわかる。このアルゴリズムの計算時間はであることが知られており、多くの母点が与えられても、実行可能な時間でボロノイ図を得ることができる。